![Featured image of post [Tech] Welch’s overlapped segmented average 白话文(3)](/p/tech/wosa_3/imgs/02_hud785c006c4a31c2c7a8a8f29f893134a_28936_800x0_resize_box_3.png)
9. Averaging and overlap
如果我们用目前讨论的方法来计算一个Spectrum(例如用一个合适的window function点乘一个时间序列的片段,进行DFT,然后处理缩放这个结果),我们会典型地得到这个结果有点"noisy"。理论证实了这一观察: 如果这个信号在这个frequency bin是随机的,那么在一个frequency bin 里,Spectrum 的标准差等于它自身,像是100%。提升DFT的长度N不能够改善这个情况,因为提升DFT的长度N仅仅减小frequency bin的宽度,而不提高方差。
通常的补救方法是对这个频谱取M的平均,然后可以通过一个因子 $1/\sqrt{M}$ 来减小这个被平均的标准差的输出。然而,在这个平均的过程,这个信号的属性必须仍然不变的。注意到这个平均一定要从Power Spectrum或者Power Spectral Density出发,而不是从它们的方根:Linear Spectrum或者Linuar Spectral Density出发。如果想要这个方根作为结果,它们一定要在完成平均后的最后再计算。如果与窗函数一起使用,这个平均几个spectra的方法也叫做"Welch’s method of averaging modified periodograms"或"Welch’s overlapped Segmented average"等。
- 当这个spectra是被平均的,这个spectra的方差/标准差可以用很小的额外计算资源同时被计算。这个标准差对"自身估计的平均"的比率给出了一些"在某frequency bin占主导地位的信号的随机性"指示:如果是像噪声那样的随机信号会将近一致,如果说连贯的信号像纯正弦信号会比较小。
如果一个长的连续信号流被简单地分开成几个不重叠的长度为N的片段,并且每个片段用window function和DFT处理,我们有一个情况如图7所示:
由于,典型地,窗函数的边界非常小或者接近于0,这个数据流的一些重要的部分在这种分析里已经被忽略。如果数据流是用很高的成本产生,并且信息很有可能要从被忽略的部分中提取,显然在这种情况分段窗函数处理很不好,(当然也有可能是积极的一面,如果原始数据以几乎无限的数量廉价提供时)。这个情况可以被提高用"片段重叠"的方法,如图8所示:
多少片段需要重叠呢?这取决于窗函数,也取决于需求。对于时域上相当宽的窗函数(例如Hanning),通常50%的值用于重叠。对于更窄的窗函数(例如flat-top windows),用更高的重叠率(高达84%)是合适的。
再选择最好的【重叠量】的时候,必须找到结果数据权重的【平坦】与计算消耗之间的妥协。各个window function的描述,在附录C中,包含一个图展示三条可以帮助选择适当的窗函数的曲线。图9展示了Hanning window的这三条曲线: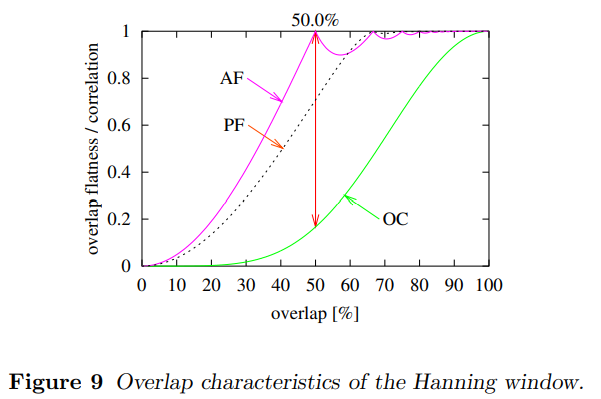
Amplitude Flatness(AF):
当几个重叠窗函数被应用到数据流,每一个数据点被不同权重地采样几次。每个数据点的总权重的可能结果,是所有被应用到那个数据点的所有窗值的和。图10画出对于Hanning窗带有33%的重叠(33%小于最优值50%,这个图选择33%主要是为了画图)的这个情况。如果我们假设所有我们的数据点有同样的有效性,我们想要这个"和"对于每个数据点保持一致的常数。这个Amplitude Flatness (AF) 是 应用到任何数据点的最小总权重 对 最大总权重 的比值,对于一个确定值的重叠可以被唯一确定。在这个图10展示的例子,它是0.5。对于Hanning窗,这个总和窗值的曲线变得恰好的平整对于50%的重叠,这样Amplitude Flatness (AF) 达到它的最优值,1.0,在这个情况。对于更多其他window function,没有这样一个独特的点,但是随着重叠数量的增加,amplitude flatness仍然非常快地接近1.0。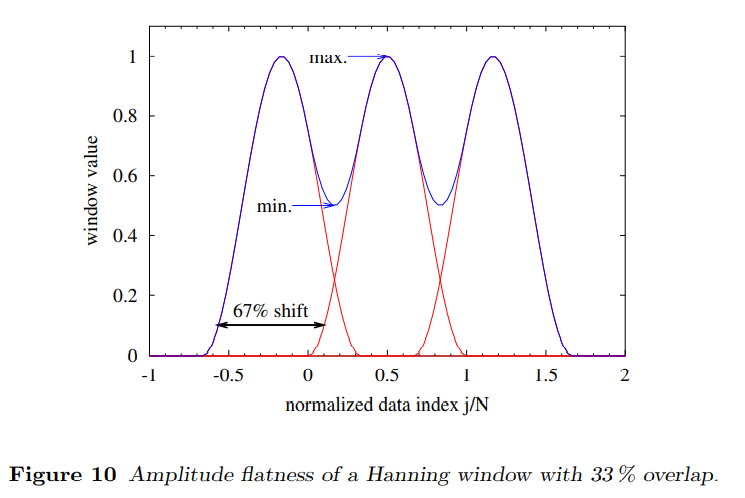
Power Flatness(PF):
因为window value的线性和(同样在上面的amplitude flatness定义中获得)适用于正弦信号的振幅,但不相干的信号例如noise必须被二次地加上去。因此我们定义Power Flatness (PF) 类似于上面的amplitude flatness,但不同的是,window function 的 window value 被二次相加。这个Amplitude Flatness 和 Power Flatness 的概念受到类似讨论的激励,在[Trethewey2000].
Overlap Correlation(OC):
如果这个重叠变得太大,即使信号是随机的,从后续的拉伸计算的spectrum也会变得强相关。一个高的相关性意味着浪费了计算工作。对于重叠"r",这个重叠相关性(Overlap Correlation, OC)计算如下:
当对重叠选择一个值,一方面,为了对所有数据给出相等的权重,我们会想要它尽可能平(flatness)。在另一方面,我们想要overlap correlation变小,这样不用重复地计算高相关性的结果而浪费计算资源。为了了解一个适合的重叠,我们有点武断地定义"recommended overlap (ROV)",这是当AF和OC的距离达到它的最大值(如图9)时候的重叠的值。对于Hanning window,当重叠值是50%的时候这个AF和OC的距离达到最大值。这个定义恰好为本文所有的窗口产生了合理的结果。
本段小结:
- 直接得到的Spectrum的噪声floor可能看起来波动很大,解决方法是求附近几个frequency bins的平均。
- 直接分段套窗函数可能会丢失信号的一些重要信息,因此可以采用"重叠"的方法,这个值取决于窗函数的选择,窗函数表给出的ROV值是建议的重叠值。在这个值下,振幅平坦度(AF)高,重叠相关度(OC)小,是理想的妥协。
10. Preprocessing of the data: DC and trend removal
经常输入到我们算法的时间序列会有非零的DC分量,虽然这个DC分量可能随时间缓慢地变化。这样一个DC分量会展示在 spectrum 结果的第一个 frequency bin (m=0) 中。如果一个window function被用或者平均值随着时间改变,这也会泄漏到邻近的frequency bins,可能掩盖掉低频信号。
由于scale问题(看Section 8),或者因为有更简单和更好的方法来测量它(例如,简单地求平均或者数字低通滤波器),作为DFT处理的结果,这个DC平均通常我们不感兴趣。
因此我们通常想要从数据中去除它,在DFT处理之前。这里有几个方法来完成这个任务,(大致)按照完善的顺序递增:
- 在分段前,计算整个时域的平均值,对所有数据点减去这个平均值。
- 在分段前,对整个时域,从第一个数据点到最后一个数据点,计算一条直线,对所有数据点减去这条直线。
- 在分段前,通过线性回归计算整个时域的"平均趋向"(average trend),对所有数据点减去这条直线。
- 在应用窗函数前,计算每个片段的平均值,对每个片段的数据点减去这个平均值。
- 在应用窗函数前,从每一个片段的第一个数据点到最后一个数据点计算一条直线,对片段的所有数据点减去这条直线。
- 应用窗函数前,通过线性回归计算每个片段的"平均趋向"(average trend),对片段的所有数据点减去这条直线。
- 时域信号通过一个高通滤波器(DC-Blocker)。
使用上述的哪一个程序取决于实际情况。如果DC分量已经知道是可以忽略不计的(例如,因为存在AC耦合),或者对低频frequency bin不感兴趣,这样的话去除DC这一步骤可以被忽略。在另一方面,在一些情况(例如,大量数据的小波动,例如小变化在Hz范围,然而拍频在GHz范围)甚至必须防止FFT算法的数值崩溃。
对于一个通用的算法,输入信号的特性是未知的,建议至少使用一个上面的简单版本的程序,因为它们对比后面的处理很花费很少,能提高最低频率的frequency bins的有效性,并且能防止垃圾数据的产生。
11. Putting it all together
这里建议怎样把所有上面提到的细节放在一起形成一个可以工作的算法。当然,这不一定是最好的。一些独立的步骤可以被省略掉,或者这个顺序也许可以根据实际情况来进行替换。
- Input data: 我们假设有一长串数据流已经被转换成浮点数(对应于ADC输入的"Volts"),对应Section 3。我们也假设采样频率$f_s$是已知而且不变的。
- Frequency resolution and length of DFT: 现在选择一个频率分辨率(frequency resolution)$f_{res}$。典型值在 $f_s/100$到$f_s/100000$之间。找到这个符合的DFT长度N,根据$N = f_s/f_{res}$ 。让N等于下一个方便的值(像是2的幂),然后重新计算最终的 frequency resolution $f_{res}=f_s/N$。
- Window function: 可以选择一个窗函数并计算它的值。第一个决定是需不需要"flat-top window"。如果正弦peak 的 amplitude需要从spectrum被测量的话需要"flat-top window"。否则,其他window是更好的选择,因为它们有更小的带宽。通常的规则是,尝试选择一个旁瓣压制不小于输入信号固有的信噪比的窗。如果SNR是未知的,可以从Hanning window开始然后从结果的Spectrum探测最高peak比background noise高出多少。用这个信息,选择一个合适的window。好的选择有 Kaiser window,以及新的flat-top windows 如 “HFTxx”
因为DFT的长度N是已知的,现在这个窗值$w_j$可以被计算。与此同时,计算"window sums" S1和S2(Equation 19)。如果重叠是需要的,选择一个合适的重叠值,例如从Table2,或者所选窗的描述。记录$f_{res}$,NENBW and ENBW (Equations 21 and 22) - Splitting of the data stream: 识别连续的有用数据(例如没有小故障、脉冲、丢失的周期等)分成长度为N的片段,并重叠需要的部分。如果有需要,根据Section 10去除每个片段的DC分量或者DC趋势。
- FFT: 每一个片段与已经计算好的window values $w_j$ 点乘,把结果送到 real-to-complex FFT算法。解压这个结果,计算magnitude的平方,并分别平均每一个frequency bin(如果需要)。
- Scaling: 在所有片段已经处理好后,根据Section 8 缩放这个平均,用Equation 23 或 Equation 24。如果需要得到Linear Spectrum / Linear Spectral density,应用Equation 25 或 Equation 26。最终,如果有需要,根据Section 5那样转换成其他单位。
13 Testing the algorithm
一旦把所有上面提到的流程放在一起,测试这个程序是重要的。最简单的方法是用人工定义的测试数据。这样一个数据应该包含一个或者几个已知amplitude(能在spectrum导致锐利的peak)的正弦信号,和一个带有已知的spectral density 的 noise background。虽然生成一个sine信号很直接了当,但通常不清楚怎样生成带有已知spectral density的噪声。最简单的方法是用【量化噪声】。通过选择合适的$U_{LSB}$来量化这个时域数据,一个noise floor可以被Spectrum显示有以下的density。
$$ \widetilde{U}_{dig} = \frac{ U_LSB }{\sqrt{6\cdot f_s}} $$
如果,然而,信号由一个sine wave和一个"与采样频率谐波相关"的频率组成,理想正弦波和它的圆化样本之间的偏差(导致噪声基底)是重复的,因此没有白色功率谱。通过用两个正弦波和至少一个"不与采样频率谐波相关"的频率,这个效果可以被避免,noise floor可以被当作白噪声。
14 MATLAB pwelch function
因为很多人用到这个方法,MATLAB里包含一个函数实现Welch’s method (在"Signal Processing Toolbox"里,叫"pwelch"),本文结合正文中的约定简要地讨论这个函数。
这个函数调用方式:
[Pxx, f] = pwelch(x, nwin, noverlap, nfft, fs)
这里x是一个带有时间序列的向量,nwin可以是一个整数(使用Hamming窗的长度),或者是一个保存了window weights $w_j$ 的向量,noverlap是一个整数(一部分FFT长度)表示想要的重叠,nfft是一个整数指定FFT的长度N(nfft应该跟窗函数nwin一样长度),fs是采样频率。
结果Pxx是一个装有Poert Spectral Density (PSD)的向量,f是一个向量装有与之相关的频率。如果y是输入时间序列的单位,那么Pxx的单位是 $y^2/Hz$
如果我们比较pwelch和Section 11的功能,我们发现:
- pwelch很接近我们想要的,除了消除DC平均或trend的功能。
- 如果你想要用自己的窗函数,你只能先计算然后输给向量nwin
- MATLAB 采用 FFTW package这意味着我们有Equation 9那样同样的灵活性来选择N。 $$ N=2^a 3^b 5^c 7^d 11^e 13^f $$
- pwelch主要缺乏的是它仅仅计算power spectral densities (PSD)并且没有默认方法来计算Power Spectra (PS) 或者缺失的因子在PSD和PS之间,它叫做equivalent noise bandwidth(ENBW)。如果你计算你自己的窗函数(这是推荐的),那么,很简单地就可以从Equation 22得到:
The effective noise bandwidth ENBW is given by:
$$ ENBW = NENBW \cdot f_{res} = NENBW \cdot \frac{f_s}{N} = f_s \cdot \frac{S_2}{(S_1)^2} $$